
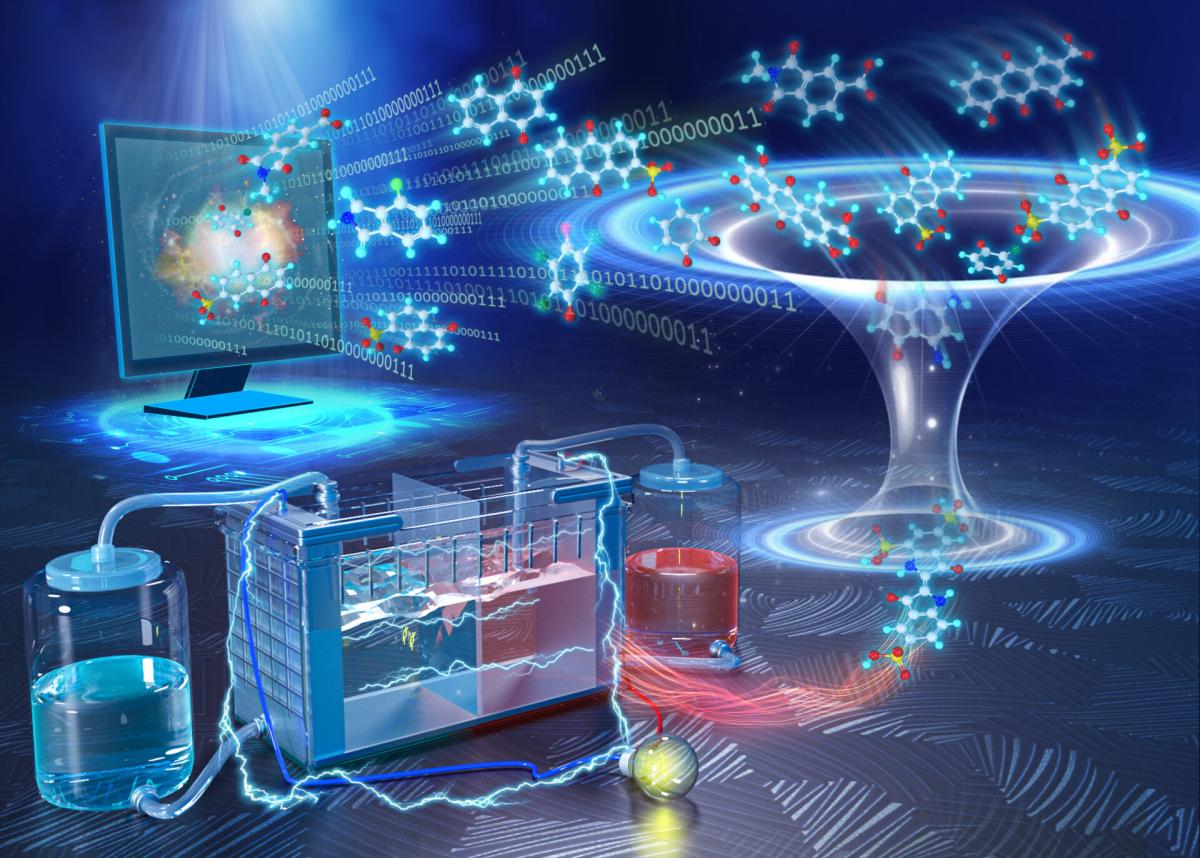
Científicos del Instituto Holandés para la Investigación de la Energía Fundamental (DIFFER) han creado una base de datos de 31.618 moléculas que podrían utilizarse en futuras baterías de flujo redox. Estas baterías son muy prometedoras para el almacenamiento de energía. Entre otras cosas, los investigadores utilizaron inteligencia artificial y superordenadores para identificar las propiedades de las moléculas. Ahora han publicado sus hallazgos en la revista Scientific Data.
En los últimos años, los químicos han diseñado cientos de moléculas que podrían ser útiles en baterías de flujo para el almacenamiento de energía. Sería maravilloso, imaginan los investigadores del DIFFER de Eindhoven (Países Bajos), que las propiedades de estas moléculas fueran rápida y fácilmente accesibles en una base de datos.
El problema, sin embargo, es que para muchas moléculas se desconocen las propiedades. Ejemplos de propiedades moleculares son el potencial redox y la solubilidad en agua. Éstas son importantes, ya que están relacionadas con la capacidad de generación de energía y la densidad energética de las baterías de flujo redox.
31.618 variantes virtuales
Para averiguar las propiedades aún desconocidas de las moléculas, los investigadores realizaron cuatro pasos. En primer lugar, utilizaron un ordenador de sobremesa y algoritmos inteligentes para crear miles de variantes virtuales de dos tipos de moléculas. Estas familias de moléculas, las quinonas y los aromáticos aza, son buenas aceptando y donando electrones de forma reversible. Esto es importante para las baterías. Los investigadores introdujeron en el ordenador las estructuras vertebrales de 24 quinonas y 28 aza-aromáticos, además de cinco grupos secundarios diferentes de relevancia química. A partir de ahí, el ordenador creó 31.618 moléculas diferentes.
En el segundo paso, los investigadores utilizaron superordenadores para calcular casi 300 propiedades distintas de cada molécula. Para ello, el ordenador utiliza ecuaciones de la química cuántica. Dado que estas fórmulas son difíciles de resolver, se recurre a un potente superordenador.
En el tercer paso, los investigadores utilizaron el aprendizaje automático para predecir si las moléculas serían solubles en agua.
El cuarto y último paso consistió en crear una base de datos legible tanto por humanos como por máquinas. La base de datos, llamada RedDB (de Redox DataBase), contiene las moléculas y sus propiedades con una nomenclatura y descripción adecuadas.





Anastacio Lorenzo coronado.
14/12/2022